María Alloza
Tuesday, February 7, 2023 | 11 minutes
Movimientos de Datos
Introducción
Los sistemas de gestión de bases de datos (SGBD) son herramientas que nos permiten almacenar y gestionar grandes volúmenes de datos de forma eficiente. En este sentido, es importante que los administradores de bases de datos conozcan las diferentes herramientas que nos permiten realizar operaciones de importación y exportación de datos, así como las diferentes opciones que nos ofrecen para realizar dichas operaciones.
En este caso, nos vamos a centrar en los movimientos de datos entre bases de datos relacionales, así como en las herramientas que nos permiten realizar dichas operaciones.
Preparación del escenario
Para llevar a cabo la realización de este ejercicio, vamos a hacer uso del esquema SCOTT para realizar las operaciones de exportación e importación de datos.
El esquema lo podremos encontrar en este repositorio y lo emplearemos junto a Oracle Data Pump para realizar las operaciones de exportación e importación de datos.

Oracle Data Pump
Oracle Data Pump es una herramienta que nos permite realizar operaciones de exportación e importación de datos de una base de datos Oracle. Esta herramienta nos permite realizar operaciones de exportación e importación de datos de forma más eficiente que las herramientas tradicionales de Oracle, como exp y imp.
¿Qué es Oracle Data Pump Export?
Oracle Data Pump Export es una utilidad para descargar datos y metadatos en un conjunto de archivos del sistema operativo denominado conjunto de archivos de volcado.
Puede importar un conjunto de archivos de volcado solo mediante la utilidad de importación de bomba de datos de Oracle. Puede importar el conjunto de archivos de volcado en el mismo sistema o importarlo a otro sistema y cargarlo allí.
El conjunto de archivos de volcado se compone de uno o más archivos de disco que contienen datos de tabla, metadatos de objetos de base de datos e información de control. Los archivos están escritos en un formato binario patentado. Durante una operación de importación, la utilidad Oracle Data Pump Import utiliza estos archivos para ubicar cada objeto de la base de datos en el conjunto de archivos de volcado.
Debido a que los archivos de volcado los escribe el servidor, en lugar del cliente, debe crear objetos de directorio que definan las ubicaciones del servidor en las que se escriben los archivos.
Oracle Data Pump Export le permite especificar que desea que un trabajo mueva un subconjunto de datos y metadatos, según lo determine el modo de exportación. Esta selección de subconjuntos se realiza mediante filtros de datos y filtros de metadatos, que se especifican a través de los parámetros de exportación de Oracle Data Pump.
Export proporciona diferentes modos para descargar diferentes porciones de datos de Oracle Database:
-
FULL: Exporta todos los datos y metadatos de la base de datos.
-
SCHEMA: Exporta todos los datos y metadatos de un esquema de usuario.
-
TABLE: Exporta todos los datos y metadatos de una tabla.
-
TABLESPACE: Exporta todos los datos y metadatos de un tablespace.
-
TRANSPORTABLE: Exporta todos los datos y metadatos de la base de datos en un formato que se puede importar en una base de datos de destino que no sea idéntica a la base de datos de origen.
¿Qué es Oracle Data Pump Import?
Oracle Data Pump Import es una utilidad para cargar un conjunto de archivos de volcado de exportación de Oracle en un sistema de destino.
Un conjunto de archivos de volcado de exportación se compone de uno o más archivos de disco que contienen datos de tabla, metadatos de objetos de base de datos e información de control. Los archivos están escritos en un formato binario patentado. Durante una operación de importación de Oracle Data Pump, la utilidad de importación utiliza estos archivos para ubicar cada objeto de la base de datos en el conjunto de archivos de volcado.
También puede usar Importar para cargar una base de datos de destino directamente desde una base de datos de origen sin archivos de volcado intermedios. Este tipo de importación se denomina importación de red.
Importar le permite especificar si un trabajo debe mover un subconjunto de datos y metadatos del conjunto de archivos de volcado o la base de datos de origen (en el caso de una importación de red), según lo determine el modo de importación. Esto se hace mediante el uso de filtros de datos y filtros de metadatos, que se implementan mediante comandos de importación.
Ejercicio 1
Realiza una exportación del esquema de SCOTT usando Oracle Data Pump con las siguientes condiciones:
- Exporta tanto la estructura de las tablas como los datos de las mismas.
- Excluye la tabla BONUS y los departamentos con menos de dos empleados.
- Realiza una estimación previa del tamaño necesario para el fichero de exportación.
- Programa la operación para dentro de 2 minutos.
- Genera un archivo de log en el directorio raíz.
Para realizar la exportación, lo primero que deberemos hacer es concederle al usuario dueño de la base de datos los permisos necesarios para realizar la exportación.
-
Para realizar la exportación, lo primero que deberemos hacer crear el directorio donde se almacenarán los archivos de exportación.
mkdir /opt/oracle/export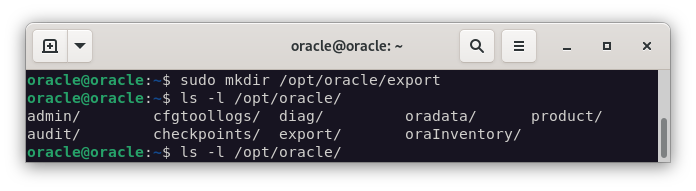
Y le cambiamos los permisos para que el usuario
oraclepueda acceder a él.chown oracle:oinstall /opt/oracle/export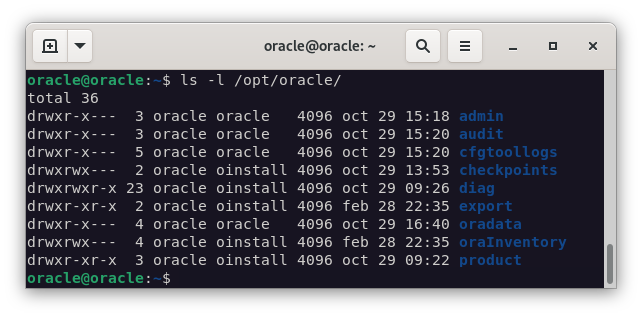
-
Nos conectamos a la base de datos y creamos un directorio en el que se almacenarán los archivos de exporración, al que le asignaremos los permisos necesarios para que el usuario
mariapueda acceder a él.CREATE DIRECTORY EXPORT_BD AS '/opt/oracle/export/'; GRANT READ, WRITE ON DIRECTORY BD_EXPORT TO SCOTT;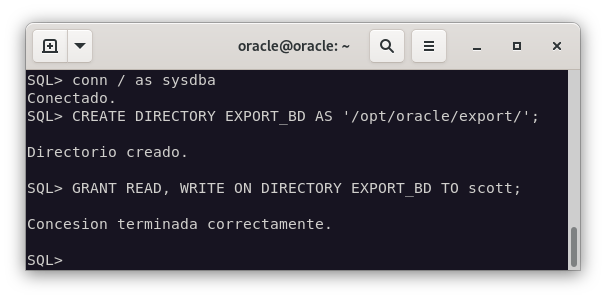
-
Le adjudicamos también permisos para que pueda exportar datos.
GRANT DATAPUMP_EXP_FULL_DATABASE TO scott;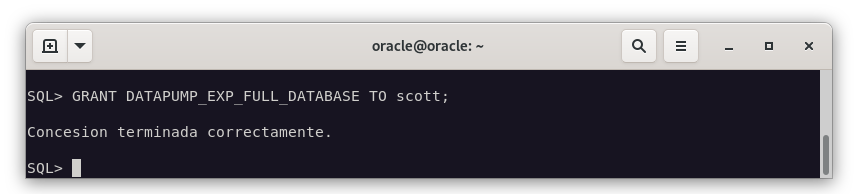
-
Ahora, exportamos el esquema de SCOTT usando Oracle Data Pump con las condiciones indicadas en el enunciado.
expdp scott/tiger DIRECTORY=BD_EXPORT SCHEMAS=scott EXCLUDE=TABLE:\"=\'BONUS\'\" QUERY=dept:'"WHERE deptno IN \(SELECT deptno FROM EMP GROUP BY deptno HAVING COUNT\(*\)>2\)"'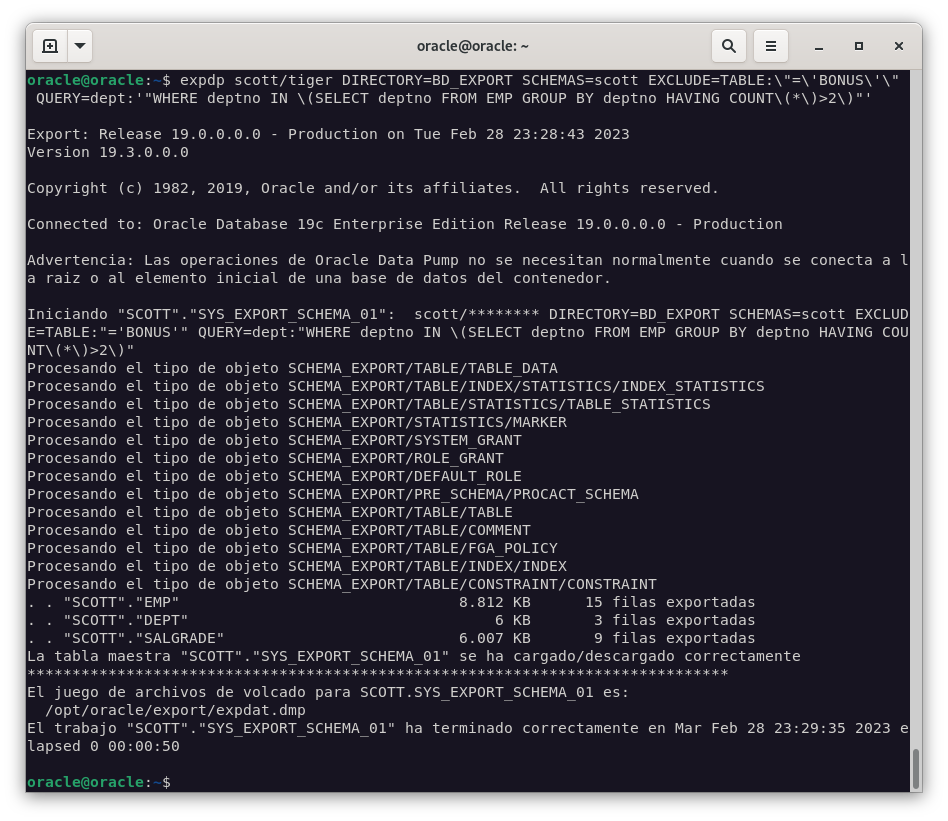
-
Para realizar la exportación tras 2 minutos, podemos realizarlo a través del comando
at now + 2 minuteso bien, como realizaré en mi caso, con un script que ejecutará la exportación tras 2 minutos.#!/bin/bash echo "Exportación de SCOTT en 2 minutos" sleep 60 echo "Exportación de SCOTT en 1 minuto" sleep 30 echo "Exportación de SCOTT en 30 segundos" sleep 27 echo "3..2..1" sleep 3 expdp scott/tiger DIRECTORY=BD_EXPORT SCHEMAS=scott EXCLUDE=TABLE:\"=\'BONUS\'\" QUERY=dept:'"WHERE deptno IN \(SELECT deptno FROM EMP GROUP BY deptno HAVING COUNT\(*\)>2\)"'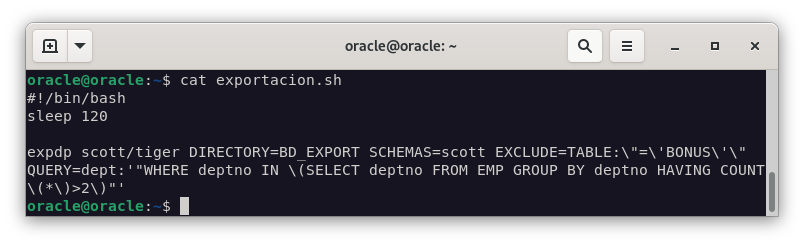
Tras crear el script, le damos permisos de ejecución.
chmod +x exportacion.sh -
Ejecutamos el script para comprobar que se realiza la exportación tras 2 minutos.
./exportacion.sh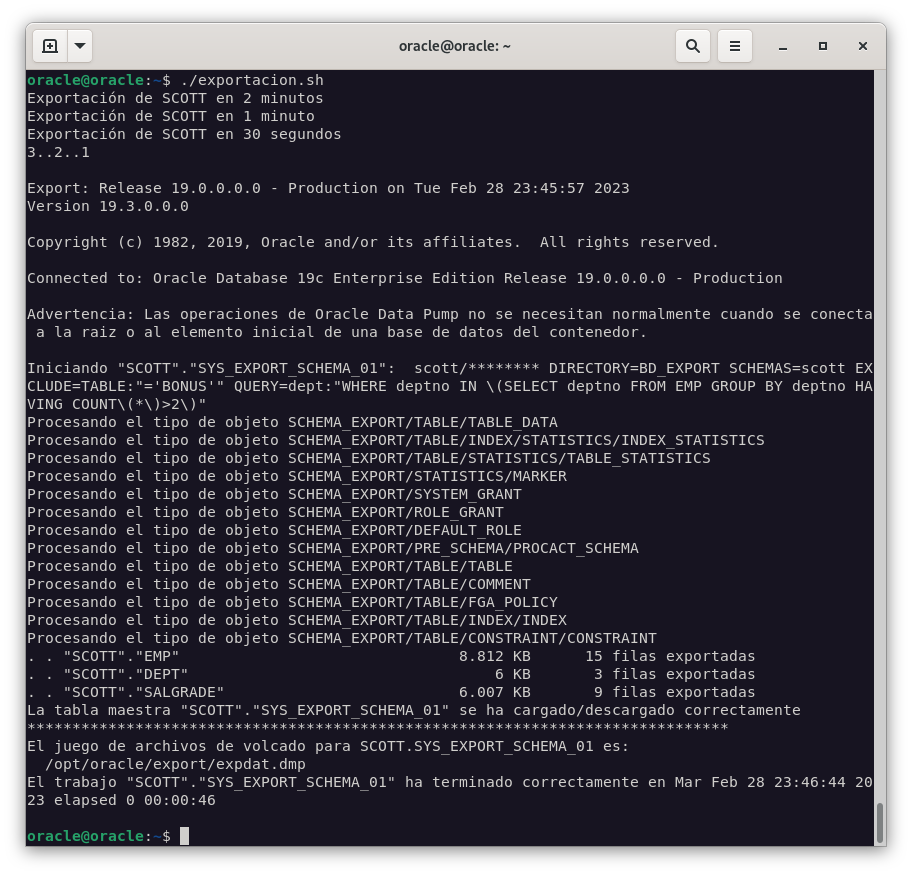
Ejercicio 2
Importa el fichero obtenido anteriormente usando Oracle Data Pump pero en un usuario distinto de la misma base de datos.
Para realizar la importación, deberemos darle permisos de lectura y escritura al usuario al que importaremos la base de datos, al directorio donde se almacenarán los archivos de importación.
GRANT READ, WRITE ON DIRECTORY BD_EXPORT TO MARIA;
Le concedemos también los permisos necesarios para realizar la importación.
GRANT IMP_FULL_DATABASE TO MARIA;
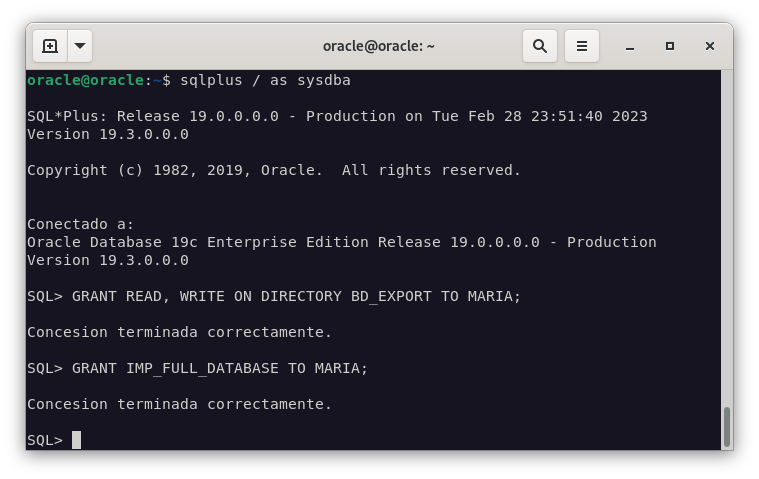
E importamos la base de datos.
impdp maria/admin schemas=scott directory=BD_EXPORT dumpfile=expdat.dmp logfile=impdat.log
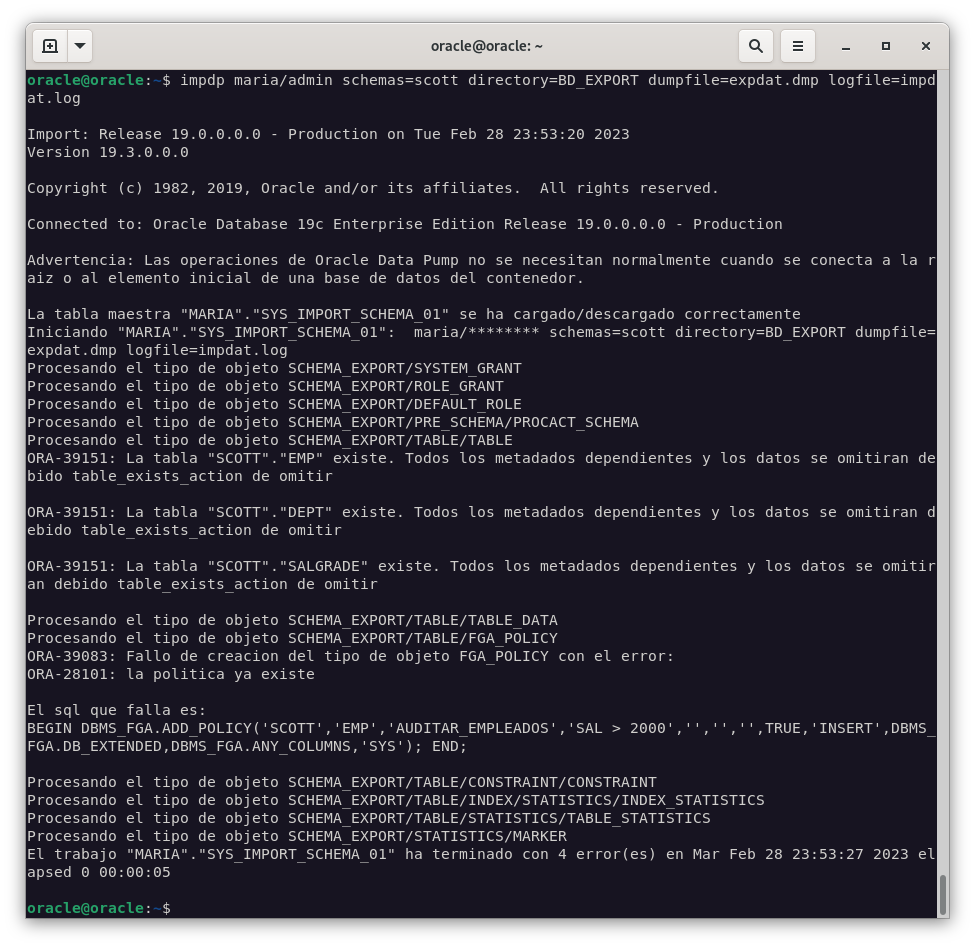
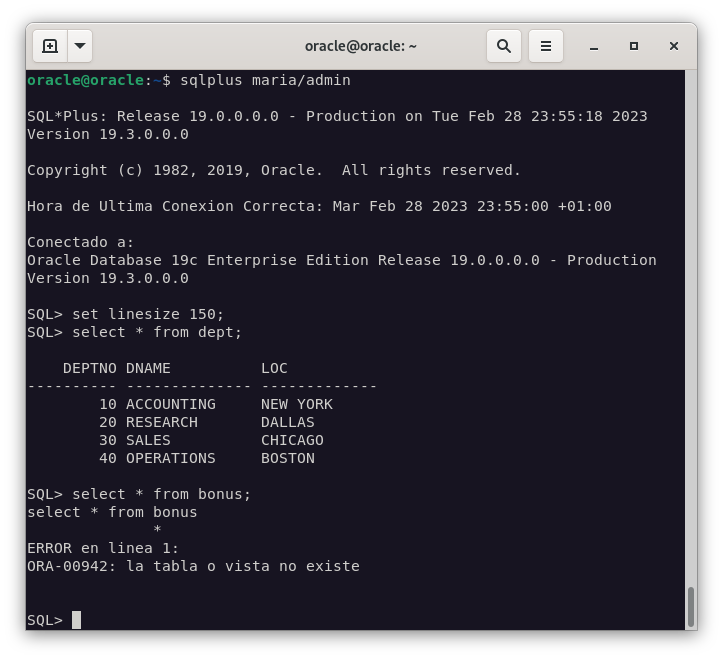
Como podemos comprobar, la importación se ha realizado correctamente y la tabla BONUS no se ha importado.
Ejercicio 3
Realiza una exportación de la estructura de todas las tablas de la base de datos usando el comando expdp de Oracle Data Pump probando al menos cinco de las posibles opciones que ofrece dicho comando y documentándolas adecuadamente.
Para realizar la exportación de la estructura de todas las tablas, y para ello vamos a utilizar las siguientes opciones:
SCHEMAS: Especifica el esquema de la base de datos que se va a exportar.DUMPFILE: Especifica el nombre del fichero de exportación.LOGFILE: Especifica el nombre del fichero de log.DIRECTORY: Especifica el directorio donde se almacenarán los archivos de exportación.CONTENT: Especifica el contenido que se va a exportar.
expdp scott/tiger schemas=scott dumpfile=scottfull.dmp logfile=scottfull.log directory=BD_EXPORT CONTENT=METADATA_ONLY
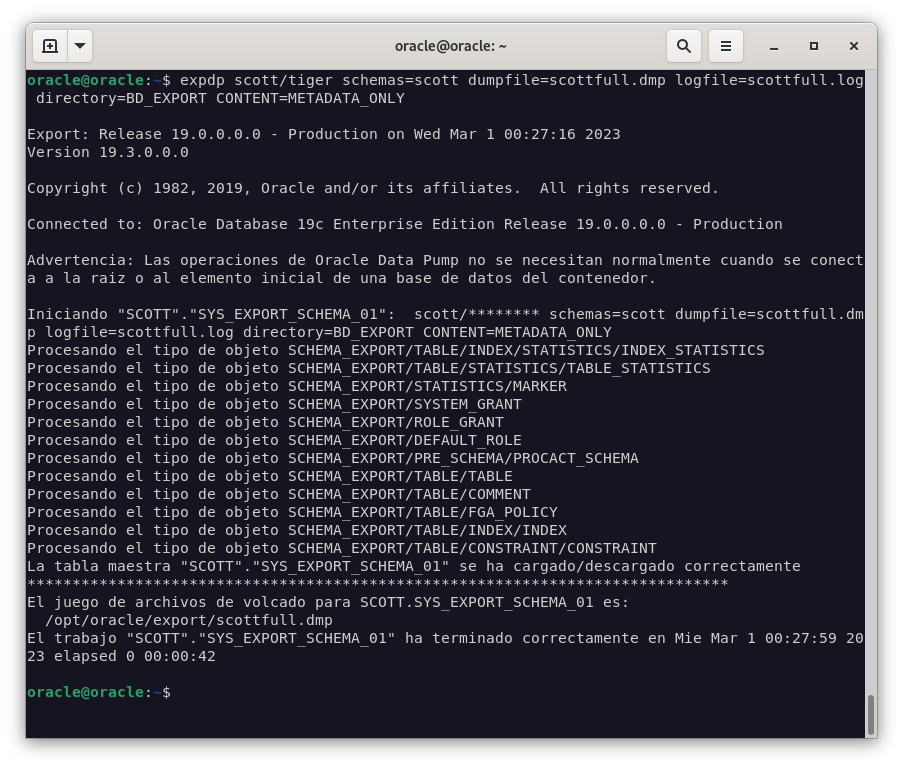

Ejercicio 4
Intenta realizar operaciones similares de importación y exportación con las herramientas proporcionadas con MySQL desde línea de comandos, documentando el proceso.
-
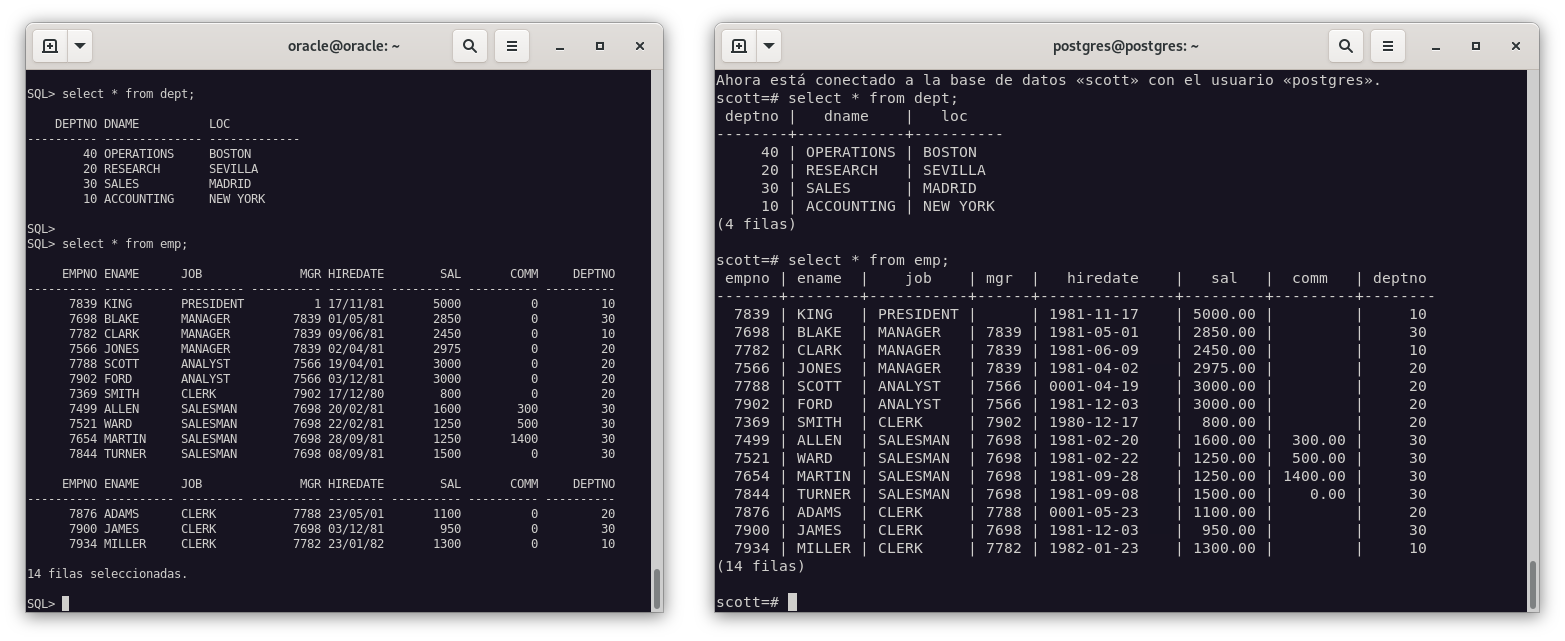
Vamos a utilizar la misma base de datos que hemos empleado en Oracle, la base de datos
scott. Para realizar la importación, lo haremos con el siguiente comando:mysql -u root -p scott < scott.sql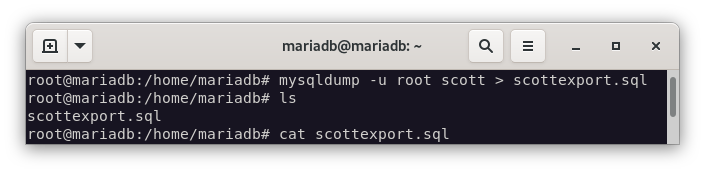
Como podemos observar, el fichero se ha creado correctamente.
-
Para asegurarnos de que la importación se realiza correctamente, contruiré una base de datos limpia para realizar la importación y comparar los resultados.
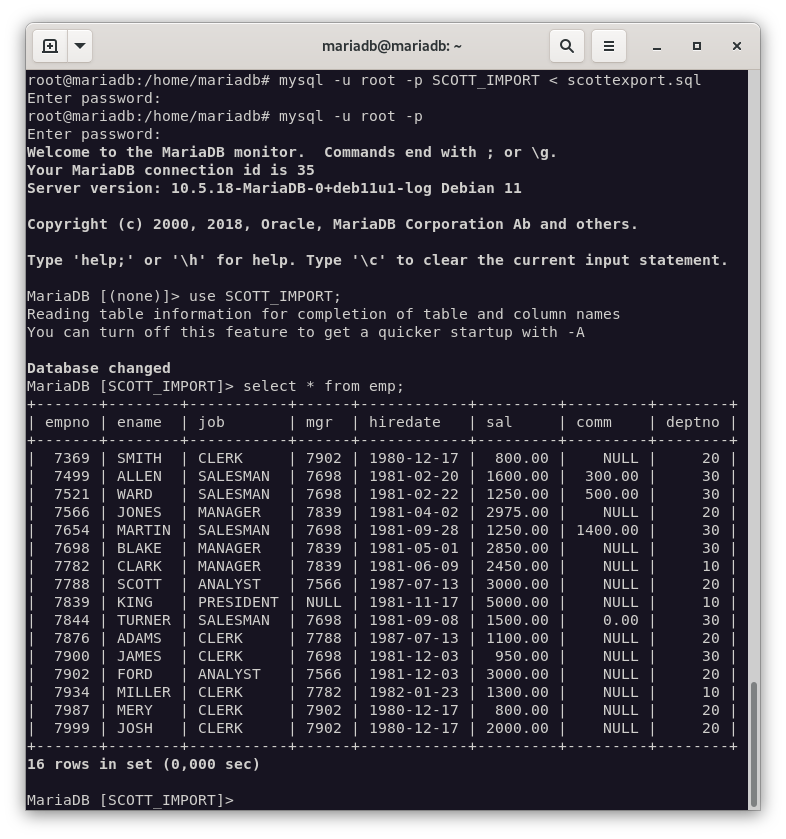
Como podemos observar, la importación se ha realizado correctamente. Hemos realizado una consulta a la tabla
EMPy los resultados son los mismos que en la base de datos original.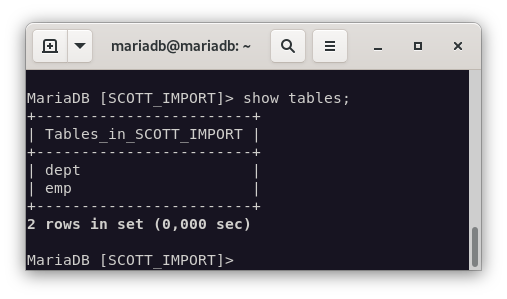

Ejercicio 5
Intenta realizar operaciones similares de importación y exportación con las herramientas proporcionadas con Postgres desde línea de comandos, documentando el proceso.
-
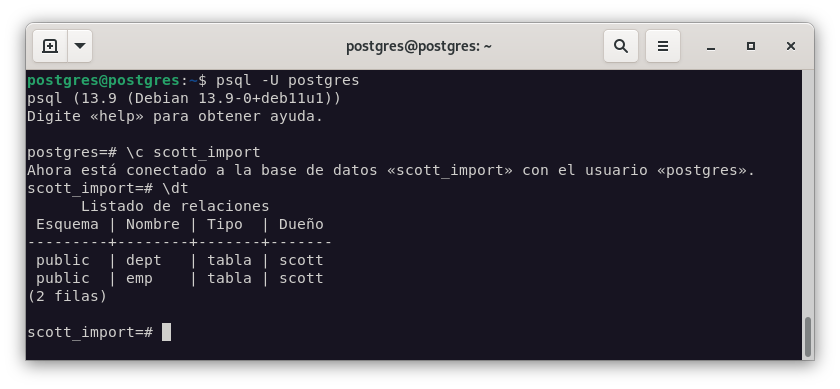
Vamos a utilizar la base de datos
scott. Para realizar la importación, lo haremos con el siguiente comando:pg_dump -U postgres scott > scott_import.sql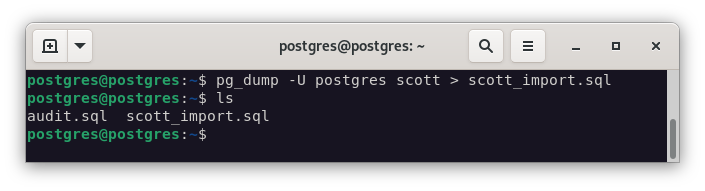
-
Para asegurarnos de que la importación se realiza correctamente, contruiré una base de datos limpia para realizar la importación y comparar los resultados.
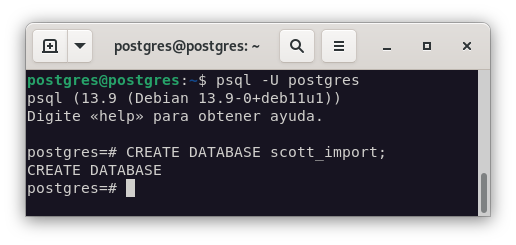
Podemos ver que la base de datos creada está totalmente limpia, y que la base de datos que vamos a importar contiene datos.
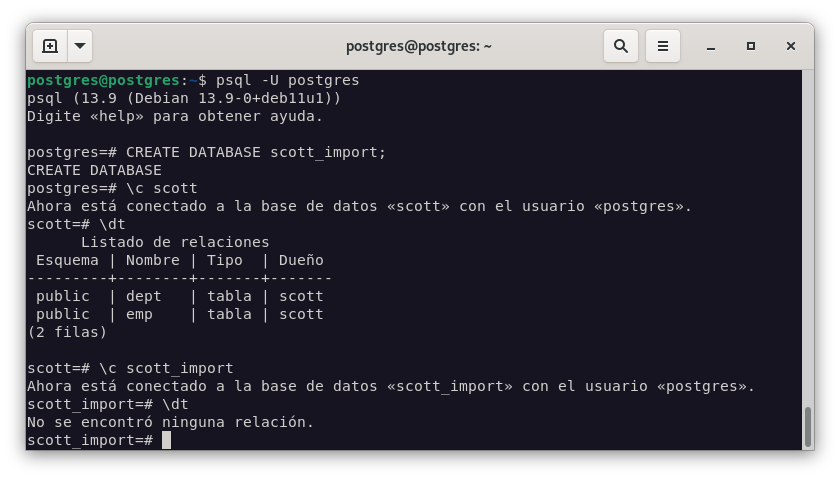
-
Importamos la base de datos con el siguiente comando:
psql -U postgres scott < scott_import.sql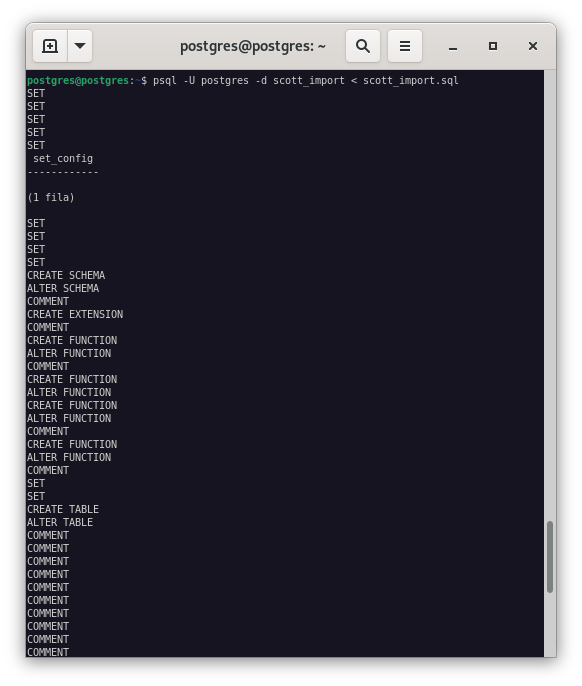
-
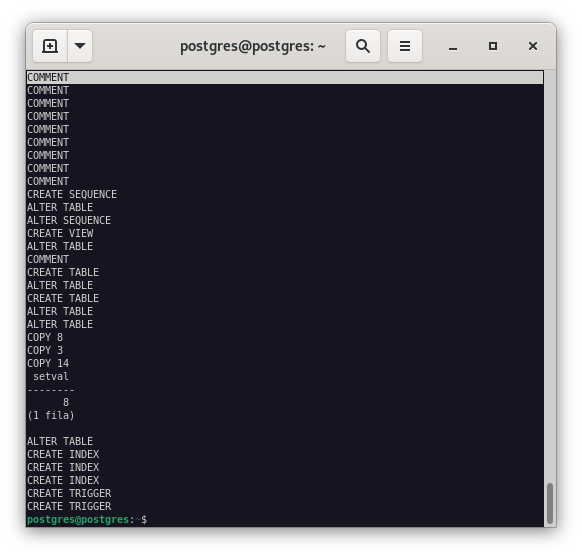
Comprobamos que la importación se ha realizado correctamente.

Ejercicio 6
Exporta los documentos de una colección de MongoDB que cumplan una determinada condición e impórtalos en otra base de datos.
-
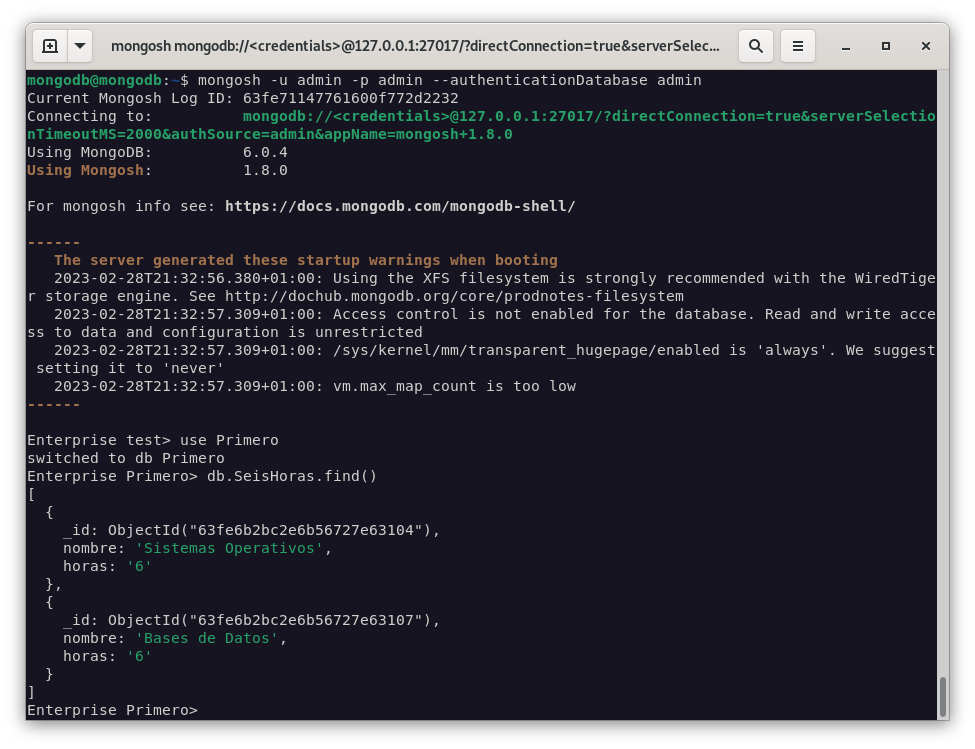
Vamos a utilizar la base de datos
asirque hemos creado en MongoDB. Pero solamente vamos a exportar los documentos que cumplan la condición de que su campo dehorassea 6.mongoexport -u admin --db admin --collection Primero --query "{\"horas\":\"6\"}" --out Primero.json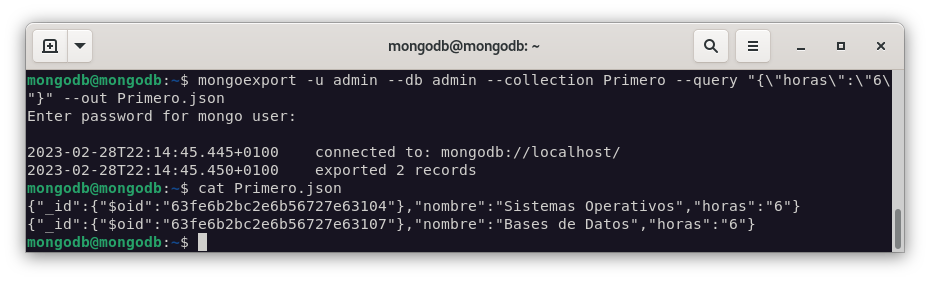
Como podemos ver en la imagen anterior, se ha exportado correctamente el fichero
Primero.json. -
Ahora vamos a importar el fichero
Primero.jsonen la base de datosasir2.mongoimport --db Primero --collection SeisHoras --type json --file Primero.json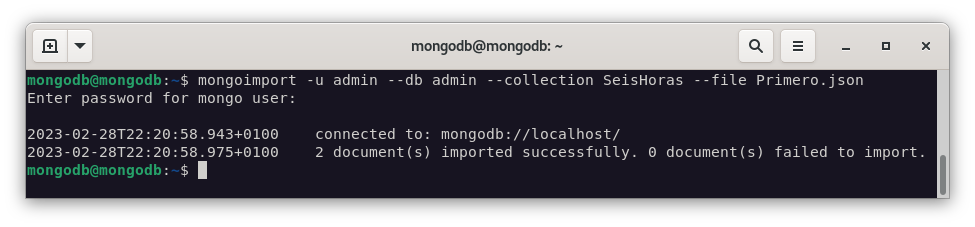
Ejercicio 7
SQLLoader es una herramienta que sirve para cargar grandes volúmenes de datos en una instancia de ORACLE. Exportad los datos de una base de datos completa desde Postgres a texto plano con delimitadores y emplead SQLLoader para realizar el proceso de carga de dichos datos a una instancia ORACLE. Debéis documentar todo el proceso, explicando los distintos ficheros de configuración y de log que tiene SQL*Loader.
Para realizar este proceso, en mi caso, voy a emplear la base de datos SCOTT que tengo en postgres de anteriores ejercicios. Estos datos los vamos a importar a un fichero csv y luego vamos a importarlos a una base de datos de Oracle.
- Función exportación a csv
Para ello, vamos a tener que realizar una función en PGSQL que nos permita exportar los datos a un fichero csv. La función sería la siguiente:
CREATE OR REPLACE FUNCTION export_csv(name_tab TEXT, ruta TEXT)
RETURNS VOID AS $$
DECLARE
name_tab TEXT;
BEGIN
FOR name_tab IN
SELECT table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format (
'COPY %I TO %L WITH (FORMAT CSV, DELIMITER '','', HEADER TRUE)', name_tab, ruta || name_tab || '.csv'
);
END LOOP;
END;
$$ LANGUAGE plpgsql;
Ahora vamos a ejecutar la función para exportar los datos a un fichero csv.
SELECT export_csv('scott', '/home/postgres/');
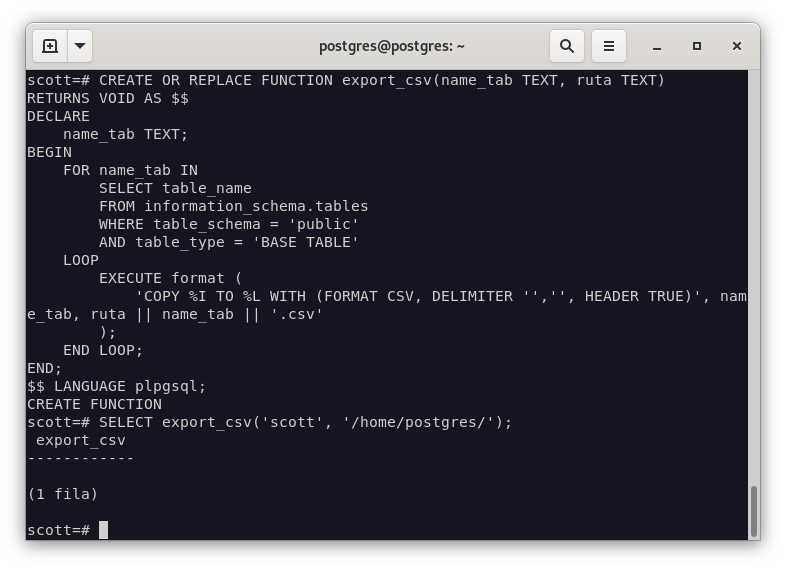
Como podemos observar, se han exportado correctamente los datos a un fichero csv.
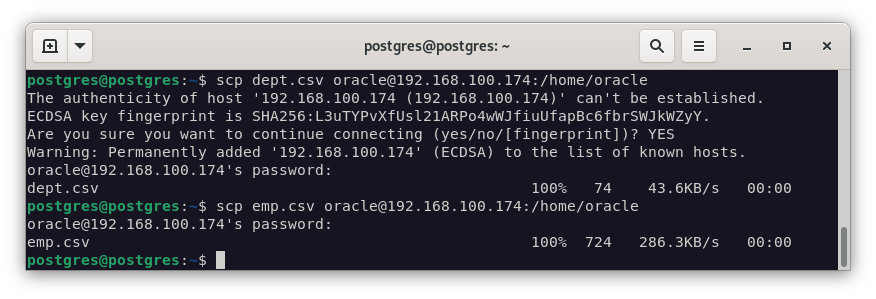
Y los pasamos por scp a la máquina de Oracle.
- Creación de ficheros de control
Ahora vamos a crear los ficheros de control para la importación de los datos a Oracle. Para ello, vamos a crear un fichero de control para cada tabla que vamos a importar. En mi caso, voy a importar las tablas EMP, DEPT y BONUS.
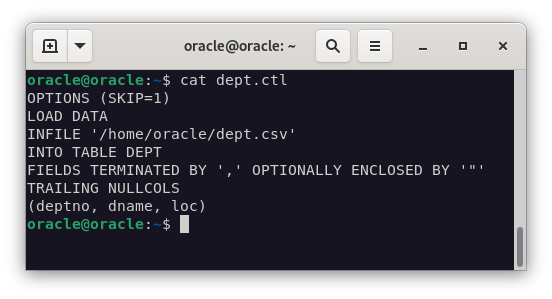
Fichero de control para la tabla DEPT
nano dept.ctl
OPTIONS (SKIP=1)
LOAD DATA
INFILE '/home/postgres/dept.csv'
APPEND
INTO TABLE dept
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(deptno, dname, loc)
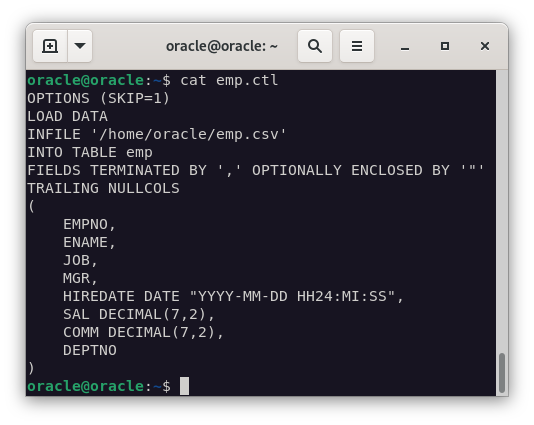
- Fichero de control para la tabla EMP
OPTIONS (SKIP=1)
LOAD DATA
INFILE '/home/oracle/emp.csv'
APPEND
INTO TABLE emp
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(EMPNO,
ENAME,
JOB,
MGR,
HIREDATE DATE "YYYY-MM-DD HH24:MI:SS",
SAL DECIMAL EXTERNAL (7),
COMM DECIMAL EXTERNAL (7),
DEPTNO)
-
Opciones empleadas
- SKIP: Nos permite saltarnos una línea del fichero de entrada.
- APPEND: Nos permite añadir los datos al final de la tabla.
- FIELDS TERMINATED BY: Nos permite indicar el delimitador de los campos.
- OPTIONALLY ENCLOSED BY: Nos permite indicar el delimitador de los campos.
- TRAILING NULLCOLS: Nos permite indicar que los campos vacíos se rellenen con
NULL. - INTO TABLE: Nos permite indicar la tabla a la que se van a importar los datos.
-
Importación de datos a Oracle
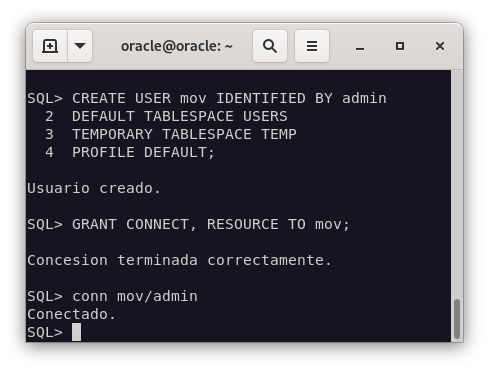
Creamos un nuevo usuario en Oracle para poder importar los datos.
CREATE USER mov IDENTIFIED BY admin;
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
PROFILE DEFAULT;
GRANT CONNECT, RESOURCE TO mov;
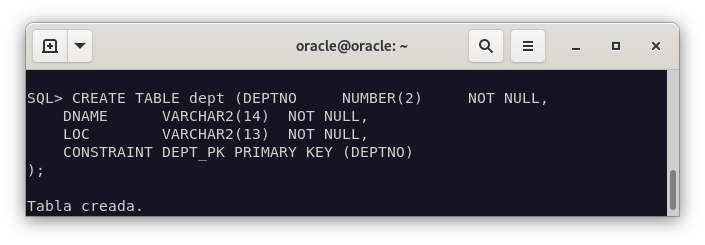
Y creamos también las tablas en Oracle.
CREATE TABLE dept (
deptno NUMBER(2) NOT NULL,
dname VARCHAR2(14),
loc VARCHAR2(13)
);
CREATE TABLE emp (
empno NUMBER(4) NOT NULL,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
);
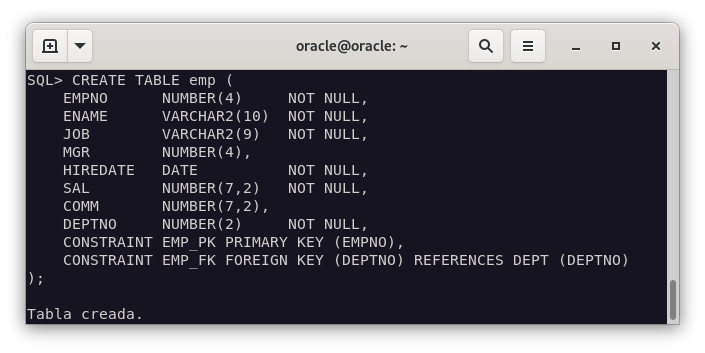
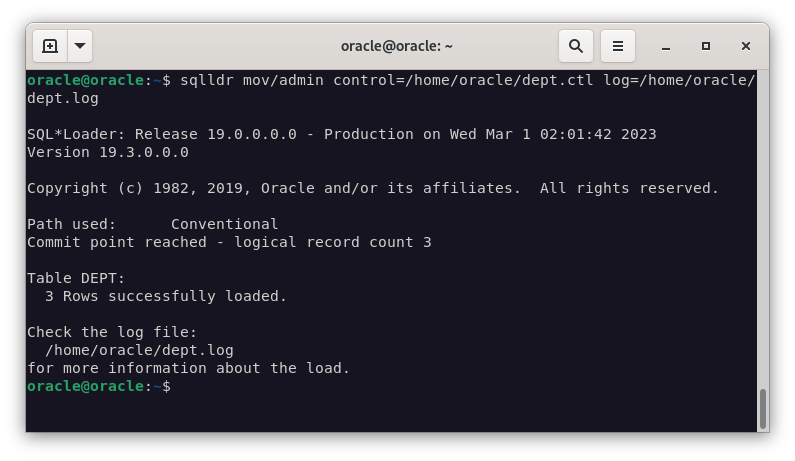
Ahora vamos a importar los datos a Oracle. Para ello, vamos a ejecutar los siguientes comandos:
sqlldr mov/admin control=/home/oracle/dept.ctl log=/home/oracle/dept.log
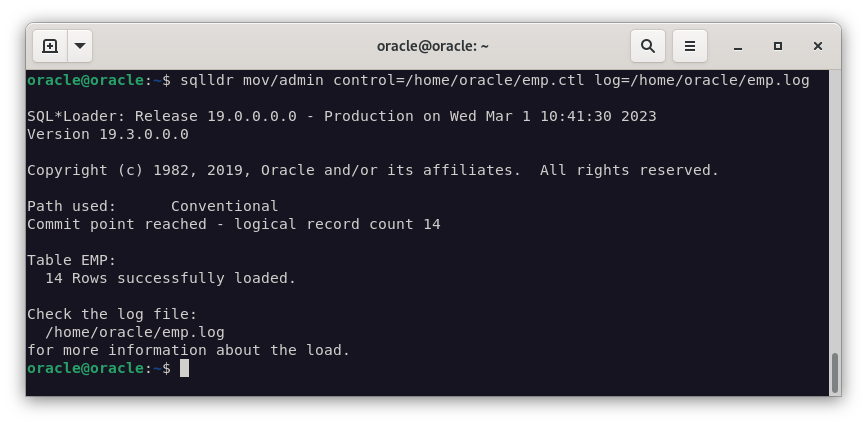
sqlldr mov/admin control=/home/oracle/emp.ctl log=/home/oracle/emp.log
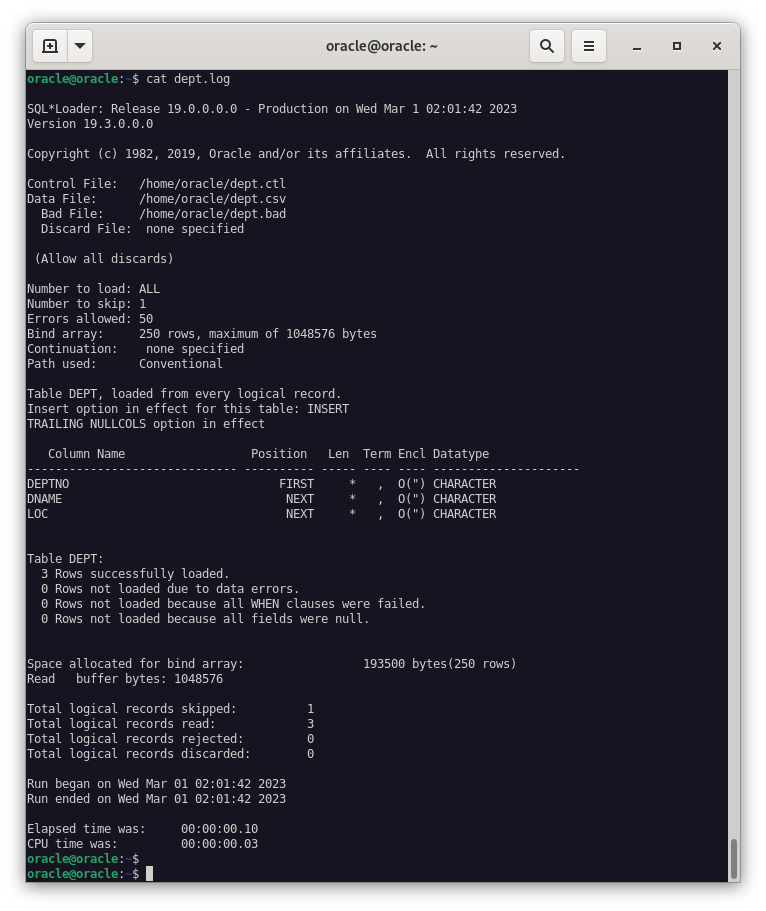
Y sus respectivos ficheros de log.
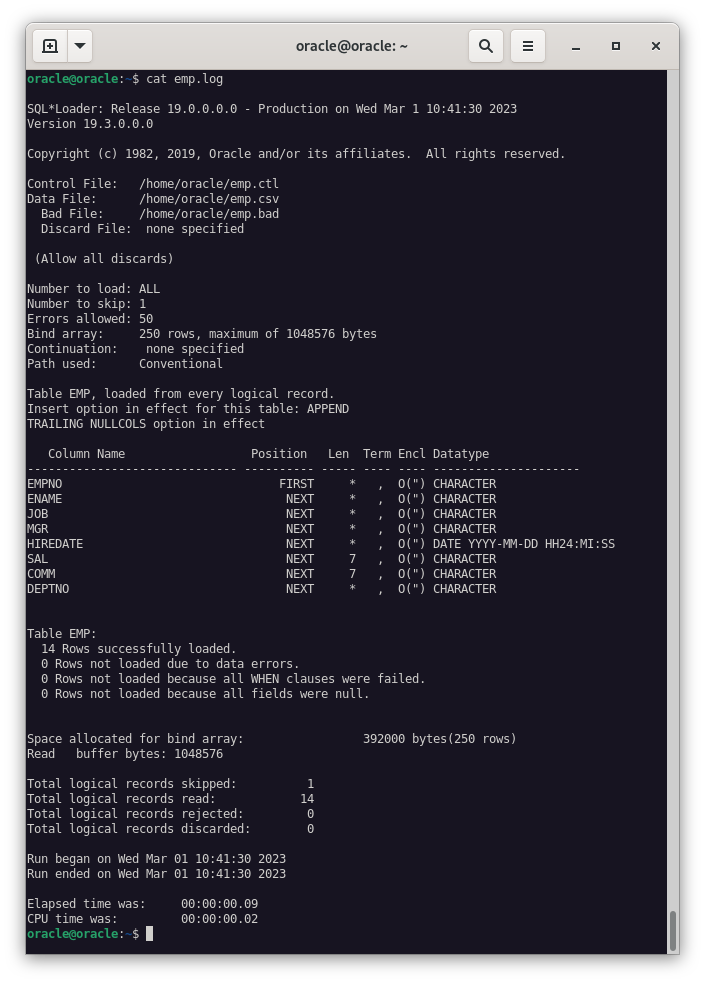
Cabe destacar, que durante el testeo de este último ejercicio, he obtenido la ayuda de mi compañero Alejandro Montes.
Como podemos comprobar, se ha realizado correctamente la importación de los datos a Oracle desde una base de datos Postgres.